
In this article, we talk about Service Discovery. Why is it important in microservices architecture, and how to set it up for your application?
What you will learn
- What is Service Discovery?
- Why is Service Discovery important in microservices architecture?
- How do you implement Service Discovery?
- What is Eureka?
What Is Service Discovery?
When we talk about a microservices architecture, we refer to a system with a large number of small services, working with each other:
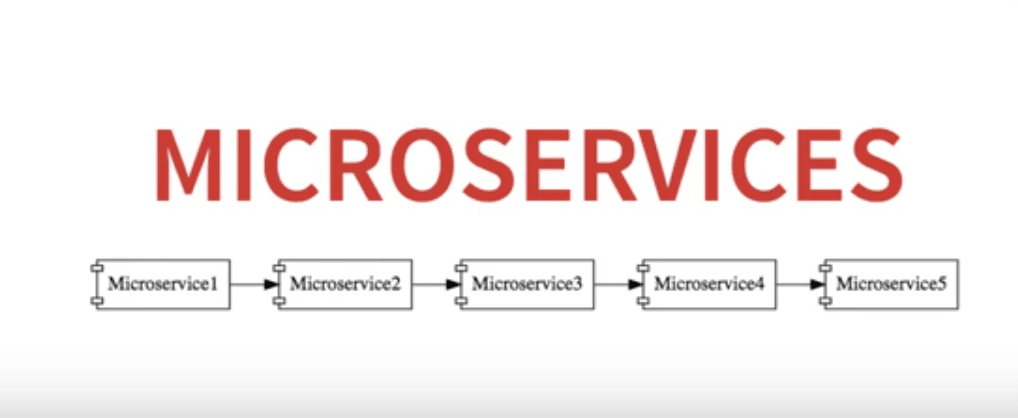
An important feature of such architectures is auto-scaling. The number of instances of a microservice varies based on the system load. Initially, you could have 5 instances of Microservice5, which go up later to 20, 100 or 1000!
Two important questions arise
- How does Microservice4 know how many instances of Microservice5 are present, at a given time?
- In addition, how does it distribute the load among all of them?
Hardcoding URLs is not an Option
One way to do this is to hard-code the URLs of Microservice5 instances, within Microservice4. That means every time the number of Microservice5 instances changes (with addition of new, or deletion of existing), the configuration within Microservice4 needs to change. This is a big headache.
Using Service Discovery
Ideally, you want to change the number of instances of Microservice5 based on the load, and make Microservice4 dynamically aware of the instances.
That’s where the concept of Service Discovery comes into the picture.
The component that provides this service is generally called a naming server.
All instances of all the microservices, register themselves with the naming server. Whenever a microservice wants to talk to another microservices, it asks the naming server about the available instances.
In the example above, whenever a new instance of Microservice5 is launched, it registers with the naming server. When Microservice4 wants to talk to Microservice5, it asks the naming server - what are the available instances of Microservice5?
Another example of Service Discovery
Using Service Discovery to identify microservice instances, helps keep things dynamic.
Let’s say there is a service for currency conversion:
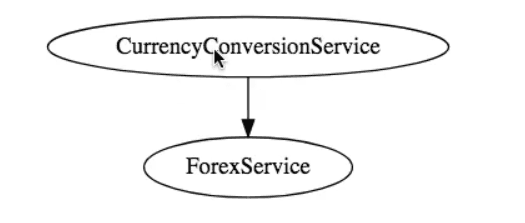
The CurrencyConversionService (CCS) talks to the ForexService. At a certain point of time, these services have two instances each:
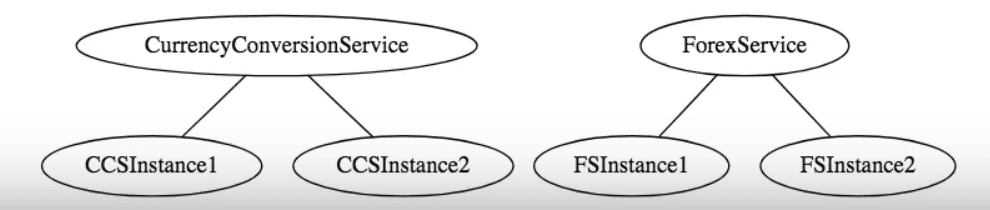
However, there could be a time where there are 5 instances of the ForexService (FS):

In that case, CurrencyConversionService needs to make sure that the load is evenly distributed across all the ForexService instances. It needs to answer two important questions:
- How does the CurrencyConversionService know how many instances of ForexService are active?
- How does the CurrencyConversionService distribute the load among those active instances?
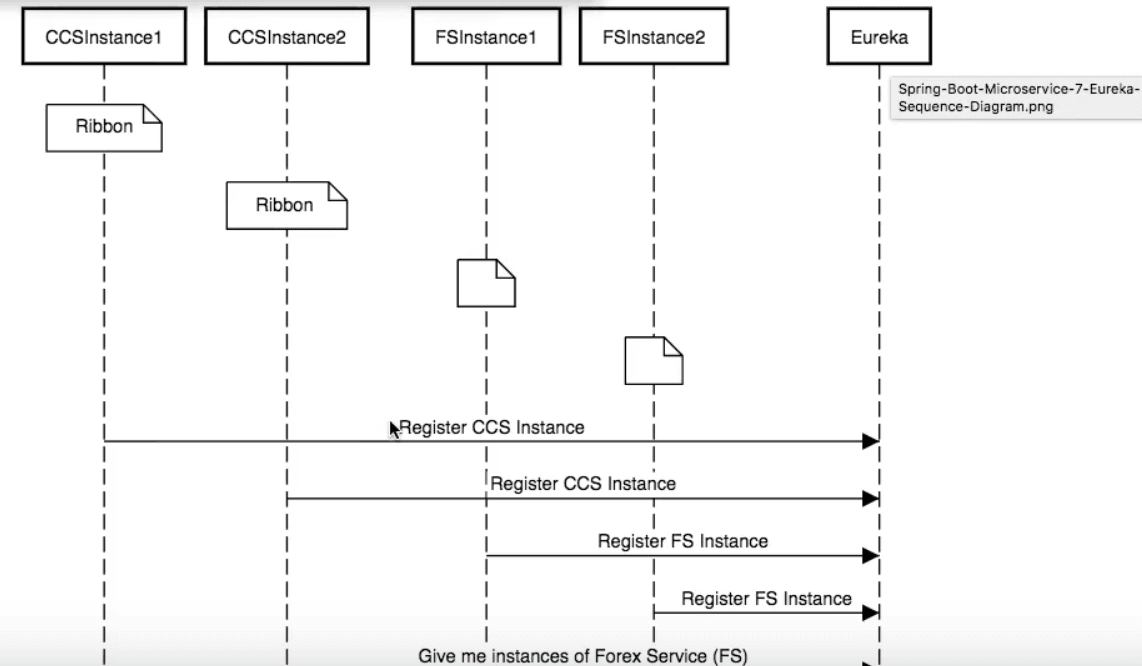
When a CCS microservice instance is brought up, it registers with Eureka. The same thing happens with all instances of FS as well.
When a CCS instance needs to talk to a FS instance, it requests information from Eureka. Eureka would then return the URLS of the two FS instances active at that time. Here, the application makes use of a client-side load distribution framework called Ribbon. Ribbon ensures proper load distribution over the two FS instances, for events coming in from the CCS.
Summary
In this video, we talked about microservice Service Discovery. We saw that microservices need to be able to communicate with each other. The number of instances of a microservice changes over time, depending on the load. Service Discovery enables us to dynamically adapt to new instances and distribute load among microservices.
Cloud and Microservices Terminology
This is the article in a series of six articles on terminology used with cloud and microservices:
- 1 - Microservices Architectures - What is Service Discovery?
- 2 - Microservices Architectures - Centralized Configuration and Config Server
- 3 - Microservices Architectures - API Gateways
- 4 - Microservices Architectures - Importance of Centralized Logging
- 5 - Microservices Architectures - Introduction to Auto Scaling
- 6 - Microservices Architectures - What is Fault Tolerance?