
Serverless Performance Tuning
Efficient configuration of AWS Lambda functions is highly critical when you’re expecting an optimal performance of your serverless applications. This blog discusses potential serverless performance bottlenecks and ways through which you can finetune AWS Lambda performance.

We’ve seen some remarkable and exponential client growth. Months over months, the number of projects that we are handling is growing at an exponential rate. And so is the expectation of exceptional service.
As we move into this article, you’ll discover that predicting the performance of Serverless systems is quite a difficult job, especially for lower-memory functions. And hence, in this blog, we’ll try to set some concrete benchmarks which you can use to configure the performance of your serverless system.
AWS Lambda Performance Benchmark 2019
- Optimal Memory Size
- Language Runtime
- Parallel Version Invocation
- Concurrency Issues
- Cold vs Hot Startups
- Code Optimization for Efficient Performance
Optimal memory size
Well, with some serverless vendors, you have the limit for choosing the memory from 128 MB to 1308 MB while some vendors select the memory automatically according to your function.
This leaves the question of how to choose the optimal memory size for your functions. What I have observed is that simply choosing the memory size that sufficiently runs your function isn’t going to work. In fact, that’s an anti-pattern. Here’s why!
Let’s take the example of AWS Lambda. Lambda provides you with a single dial to allocate the number of computing resources (RAM) to your function. This RAM allocation also impacts the amount of CPU time and network bandwidth received by your function.
Now, why is it an anti-pattern? Because Lambda billing is as accurate as 100-ms increments. Hence, opting for the smallest sufficient amount of RAM might add latency to your application. If the increase in latency outweighs the resource cost savings, it might come off as more expensive.
Well, the noteworthy point here is that you should test your lambda functions at all available resources level so as to determine the excellent level of price/performance for your application. You will observe that the performance level of your functions will increase logarithmically over time.
System Specification
The limits that you’ll set initially will be working as base limits. As you move on, you’ll come across a resource threshold where any additional RAM/CPU/Bandwidth available to your functions no longer provides any significant performance gain.
However, the prices of lambda functions increase linearly with the increase in computing resources. And that is why your test should be able to determine the logarithmic function bend to choose the excellent configuration of your function.
Performance Results
Here’s the experiment was done by AWS which clearly shows that ideal memory allocation can be cost-effective with lower latency as well. Moreover, the additional cost of computing per 100 ms for using 512 MB over the lower memory options is far better than the amount of latency reduced in the function by allocating more resources.
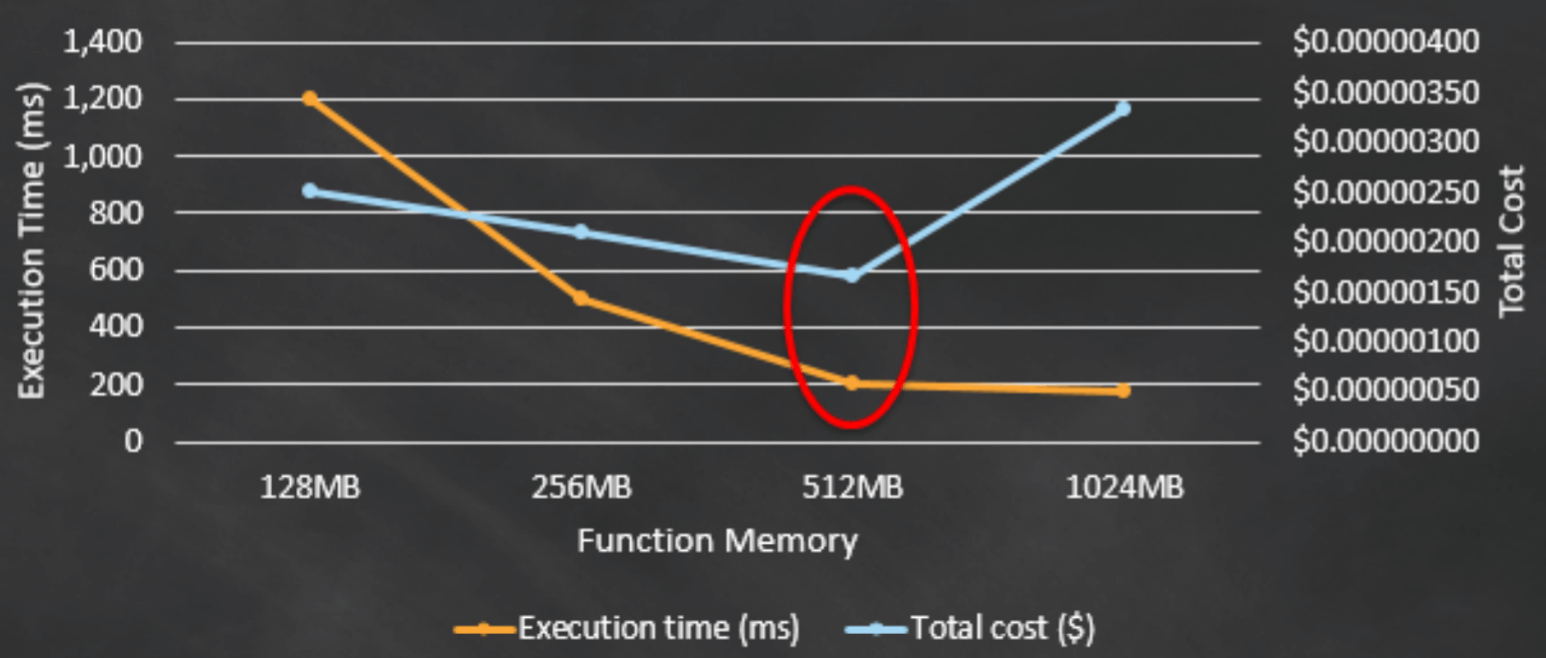
Conclusion
Though there is no significant performance gain after 512 MB for this particular logic and hence the additional cost per 100 ms now drives the total cost higher. This means, 512 MB is the optimal choice for minimising total cost.
Language runtime It could be definitely a concern of everybody, whether the chosen language will perform the performance of functions or not! But before moving on to that section, let us see which platforms support which languages.
Performance Result
This is what users from around the world have to say about language runtime performance!
#1. AWS Lambda:
As per the benchmark studies were done in 2017, compiled languages (Java & .NET) were significantly more consistent than dynamic languages (Python & Node.Js). However, one of the key advantages of writing code in Node.js and Python is that they produce much smaller size packages which result in lower cold start time.
However, according to the latest 2018 benchmark studies, there is no significant difference between newer compiled languages (.NET Core 2.0 & Go) and the original dynamic languages.
This is a remarkable achievement from AWS which gives a new level of assurance to its users. Thus, it is safer to assume that while new languages are being added to AWS Lambda, older languages are being improved at the same time.
#2. Microsoft Azure Functions:
You may come across a thin performance difference across C# and Node.js which obviously depends on each case.
At the present moment, slower startup time is observed with C# due to compilation requirements. C# does offer some deeper integration with the model exposed by the WebJobs SDK, allowing you to bind to any supported binding type, but in Node, Microsoft offers mechanisms to address most of the scenarios that would require specific binding types.
Pro tips:
Choosing a language for functions is totally dependent on your comfort and your resources.
But if the performance is the driving considerations, then you need to closely map out the performance characteristics of the languages you’re interested in and then choose the best one from them.
The compiled languages (Java and .NET) shows the best performance for subsequent invocations but for that, you’ll have to incur the largest initial startup cost for container’s first invocation. The initial invocation time of the interpreted languages (Node.js and Python) are very fast compared to compiled languages, but can’t reach the same level of maximum performance as the compiled languages do.
If your application may come across very spiky traffic or very infrequent use, we recommend one of the interpreted languages. If your application does not experience large peaks or valleys within its traffic patterns or does not have user experiences blocked on function response times, we recommend you choose the language you’re already most comfortable with.
Parallel version invocation
The deployment process in cloud functions is pretty straightforward and simple: Upload a new function code package → Publish a new version → Update your aliases. However, these steps are just the pieces of your deployment process with function.
Each deployment process would be application specific. But the cloud architects should understand the relationship between function and it’s event sources and dependencies.
Once such a concept in the deployment phase is parallel version invocation. When multiple triggering events occur faster than a single-threaded function runtime can process them, the runtime may invoke the function multiple times in parallel.
Here an existing function container containing the previous source code package will continue to invoke along with the new function version. This occurs asynchronously on the service side while updating an alias to point to a new version of the function.
The process of parallel function invocation though short-lived can affect the performance of the serverless architecture. It’s important that your application continues to operate as expected during this process. An artefact of this might be that any stack dependencies being decommissioned after a deployment (for example, database tables, a message queue, etc.) not be decommissioned until after you’ve observed all invocations targeting the new function version.
In Azure functions, if a function app is using the Consumption hosting plan, the function app could scale out automatically. Each instance of the function app, whether the app runs on the Consumption hosting plan or a regular App Service hosting plan, might process concurrent function invocations in parallel using multiple threads. The maximum number of concurrent function invocations in each function app instance varies based on the type of trigger being used as well as the resources used by other functions within the function app.
You may also like: Serverless vs Containers: Comparing your Application Deployment Options
Concurrency issues
For any basic application, multiple functions are going to execute transactions at the same time. Each transaction will perform multiple functions and may separate only by microseconds. To the users, the operations appear concurrent.
However, concurrency is one of the most important performance issues which you need to closely monitor. Otherwise, your data is vulnerable possibly undesirable effects on reads and access to uncommitted data.
Let’s compare concurrency issues by taking the example of an experiment. This experiment will help you understand the comparison of execution performance (concurrency and hot/cold startup) between AWS Lambda, Apache OpenWhisk, Google Cloud Functions and Azure Functions.
System specifications
The performance tool measures the latency and throughput of the Serverless Framework. This tool uses the Serverless Framework to deploy Node.js function to different services. It sends synchronous invocation calls by executing the function with HTTP events/triggers as per the requirements of the multiple platforms.
The memory size for all the platforms is 512 MB except Microsoft Azure, which has auto-discovering requirements of functions.
The test begins by maintaining the invocation calls to test the function by reissuing each request just after receiving the response from the preceding call. Along with this, at every 10 seconds, it adds an additional concurrent call but only up to 15 concurrent requests to the test function. Moreover, this test was repeated 10 times per platform.
Performance Results
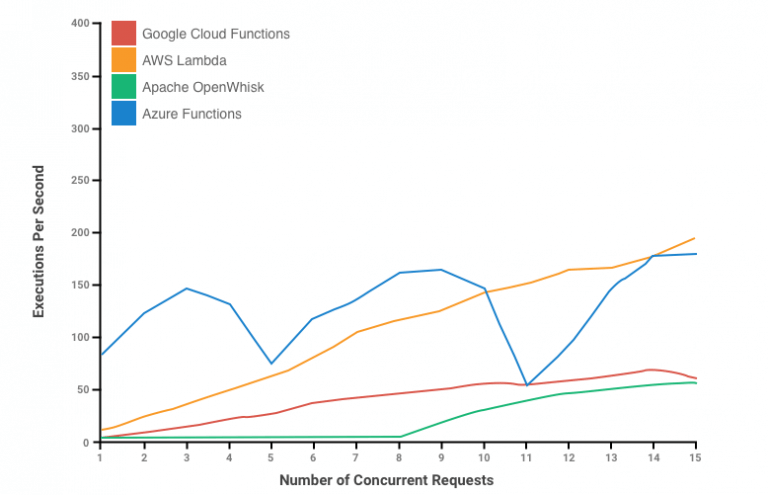
The below figure shows the results of the execution performance which measures the ability of serverless platforms.
Conclusion
Here is what we can conclude from the above graph.
- AWS Lambda: It shows to scale linearly and exhibits the highest throughput of the commercial platform even at 15 concurrent requests.
- Google Cloud Functions: It shows a sublinear scaling and appears to taper off as the number of concurrent requests approaches to 15.
- Microsoft Azure Functions: Its performance is highly fluctuating, however, the throughput observed is quite high in places, outperforming the other platforms while the concurrency level is low.
- Apache OpenWhisk: Its performance depicts a low throughput and no scalability until 8 concurrent requests and then function scales sublinearly.
Cold vs Hot startups
As we’ve discussed this inherent drawback in my previous blog about Serverless Architecture, I’ll just brief you on it.
A cold startup occurs when you execute an inactive function for the first time. This occurs when your cloud service provider provisions the runtime container selected by your function and then runs it. This process is popularly referred to as a ‘cold start’ and is known for increasing your execution time
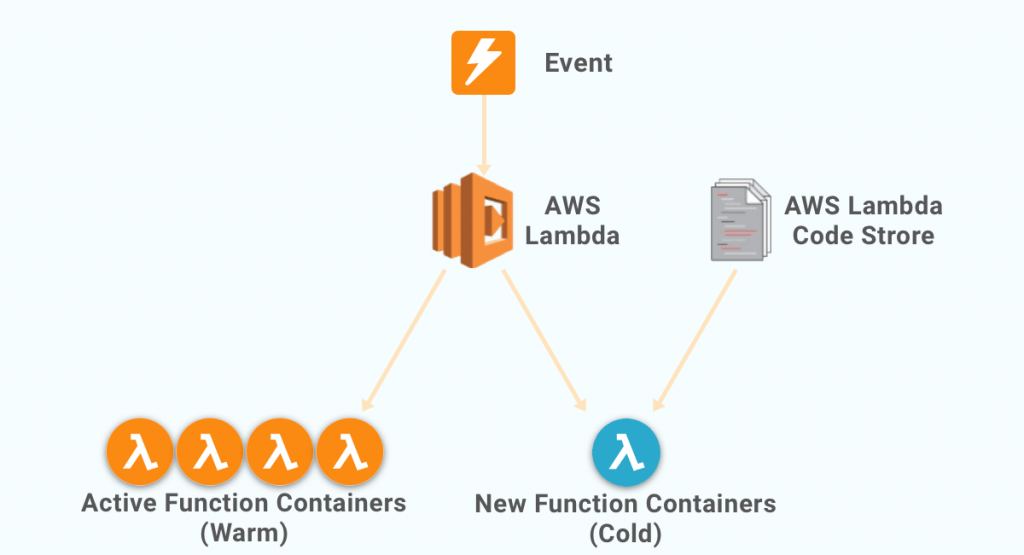
Whenever your function is running, it will stay hot, or in other sense, your container stays alive and waiting for you to command another execution. However, gradually and eventually, if there is no activity, your cloud provider will drop the container and hence, your function will become cold again.
Let’s compare concurrency issues by taking the example of an experiment. This experiment will help you understand the cold start times and expiration behaviours of function instances between AWS Lambda, Apache OpenWhisk, Google Cloud Functions and Azure Functions.
System Specification
System specification is the same as the above experiment.
This test sends a single signal execution requests to the test function at increasing intervals in the range of 1-30 minutes. Moreover, the function containers expire after 15 minutes of inactivity.
Performance Results
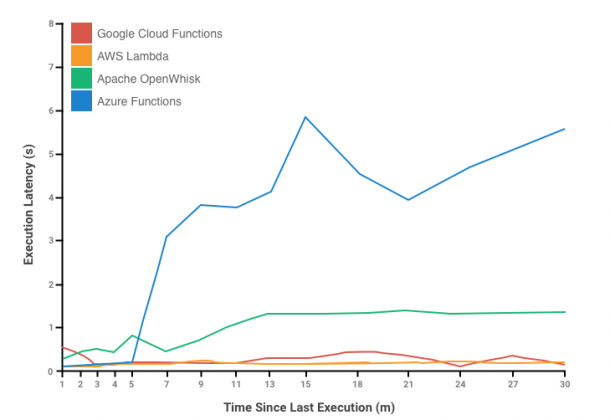
The below figure depicts the performance results of various platforms.
Conclusion
Here’s what we can conclude from the above test:
- AWS Lambda: It shows no effect of function idling.
- Google Cloud Functions: It shows no effect of function idling.
- Microsoft Azure Functions: It appears that it expires after few minutes.
- Apache OpenWhisk: It appears that it deallocates the container within around 10 minutes.
The noteworthy performance of AWS Lambda and Google Cloud Functions can be credited to the extremely fast container start times or preallocation of containers even before its execution.
Pro Tip
- Minimize the deployment package size of your function.
- Make sure you use modularity of the AWS SDK for Java and .NET.
- Also, reduce the complexities of your dependencies.
- If this isn’t sufficient, leverage the container reuse by lazily loading variables so that your function stays warm for several minutes.

Code Optimisation for efficient performance
Performance of your serverless application is hugely dependent on the logic you need the cloud function to execute and what the dependencies are. The serverless developers should understand the granularity in a microservices architecture.
If there are many function invocations it would make the application complex to run and debug. While the scope of optimization is different for each application, there are some best practices to optimize your code for functions.
Following are some of the best practices-
#1. Container reuse: Any externalized configuration or dependencies that your code retrieves should be stored and referenced locally after initial execution. The cloud architect should limit the re-initialization of variables on every invocation and use static initialization, global/static variables and singletons instead. Also, keep alive and reuse connections (HTTP, database, etc.) that were established during a previous invocation.
#2. Optimize the coding practices for deployment: The cloud functions will support many language-specific SDKs. To enable the latest set of features and security updates, cloud provider (eg. AWS Lambda or Azure functions) will periodically update these libraries. These updates may introduce subtle changes to the behaviour of your function.
To have full control of the dependencies your function uses, it is recommended to package all your dependencies with your deployment code. It is also important to minimize the package size to its runtime necessities. This will reduce the amount of time that it takes for your deployment package to be downloaded and unpacked ahead of invocation.
For example- Google functions authored in Java or .NET Core, avoid uploading the entire GCP SDK library as part of your deployment package. Instead, selectively depend on the modules which pick up components of the SDK you need (e.g. Datastore, Google cloud storage SDK modules and Google function libraries). Prefer simpler frameworks that load quickly on container startups such as Dagger and Guice.
#3.Separate the point of entry for function and core logic: For example, keep the AWS Lambda handle separate from core logic. This makes unit-testing of the function easier.
#4. Avoid long-running functions: Functions can become large and long-running due to language and external dependencies. This can cause unexpected timeout issues. Refactor large functions into smaller function sets that work together and return faster responses.
For example, an HTTP trigger function might require an acknowledgement response within a certain time limit. The HTTP trigger payload is queued to be processed by a queue trigger function. This way you can defer the actual task and return an immediate response.
#5. Initializing database connections: After a function is executed, the serverless provider (AWS Lambda) maintains the runtime container for some time. This is done in anticipation of another function invocation. So for establishing database connection leveraging global scope is very important. Instead of re-establishing the connection, the original connection should be used in the subsequent invocations.
Declare database connections and other objects/variables outside the Lambda function handler code to provide additional optimization when the function is invoked again. You can add logic to your code to check if a connection already exists before creating one.
Take Away!
Armed with this knowledge, now you can take the better decision on how to configure your functions.
The other lesson, I’d like to impart you is that function benchmarks are supposed to be gathered over the course of time and not in hours and minutes. Hence, AWS Lambda performance monitoring is a continuous process.
We’ll be refurbishing this blog from time to time and try to be updated in our custom software development practices. So, keep in touch to stay updated about AWS Lambda performance.