
Amazon Personalize - Creating a recommendation engine
AWS announced Amazon Personalize, which allows you to get your first recommendation engine running quickly, to deliver immediate value to your end user or business. As your understanding increases (or if you are already familiar with data science), you can take advantage of the deep capabilities of Amazon Personalize to improve your recommendations.
While at working , I’ve noticed increasing diversity in the application of machine learning (ML) and deep learning. It seems that nearly every day I work on a new exciting use case, which is great!
The most well-known and successful ML use cases have been retail websites, music streaming apps, and social media platforms. For years, they’ve been embedding ML technologies into the heart of their user experience. They commonly provide each user with an individual personalized recommendation, based on both historic data points and real-time activity (such as click data).
I was lucky enough to be given early access to try out Amazon Personalize while it was in preview release. Instead of giving it to data scientists or data engineers, the company gave it to me, an AWS solutions architect. With no prior knowledge, I was able to get a recommendation from Amazon Personalize in just a few hours. This post describes how I did so.
Overview
The most daunting aspect of building a recommendation engine is knowing where to start. This is even more difficult when you have limited or little experience with ML. However, you may be lucky enough to know what you don’t know (and what you should figure out), such as:
- What data to use.
- How to structure it.
- What framework/recipe is needed.
- How to train it with data.
- How to know if it’s accurate.
- How to use it within a real-time application.
Basically, Amazon Personalize provides a structure and supports you as it guides you through these topics. Or, if you’re a data scientist, it can act as an accelerator for your own implementation.
Creating an Amazon Personalize recommendation solution
You can create your own custom Amazon Personalize recommendation solution in a few hours. Work through the process in the following diagram.
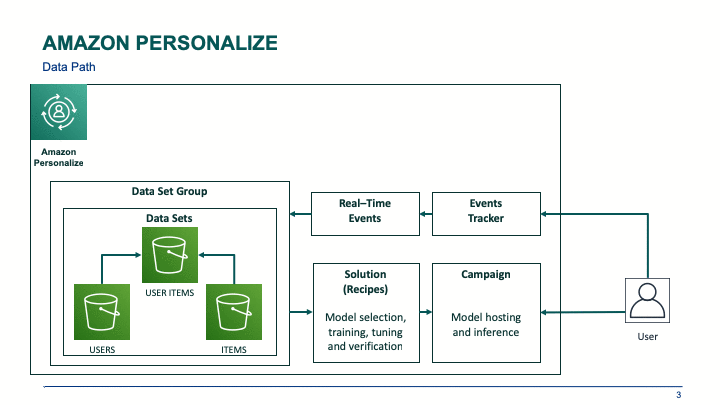
Creating dataset groups and datasets
When you open Amazon Personalize, the first step is to create a dataset group, which can be created from loading historic data or from data gathered from real-time events. In my evaluation of Amazon Personalize , I used only historic data.
When using historic data, each dataset is imported data from a .csv file located on Amazon S3, and each dataset group can contain three datasets:
- Users
- Item
- Interactions
For the purpose of this quick example, I only prepared the Interactions data file, because it’s required and the most important.
The Interactions dataset contains a many-to-many relationship (in old relational database terms) that maps USER_ID to ITEM_ID. Interactions can be enriched with optional User and Item datasets that contain additional data linked by their IDs. For example, for a film-streaming website, it can be valuable to know the age classification of a film and the age of the viewer and understand which films they watch.
When you have all your data files ready on S3, import them into your data group as datasets. To do this, define a schema for the data in the Apache Avro format for each dataset, which allows Amazon Personalize to understand the format of your data. Here is an example of a schema for Interactions:
{
"type": "record",
"name": "Interactions",
"namespace": "com.amazonaws.personalize.schema",
"fields": [
{
"name": "USER_ID",
"type": "string"
},
{
"name": "ITEM_ID",
"type": "string"
},
{
"name": "TIMESTAMP",
"type": "long"
}
],
"version": "1.0"
}
In evaluating Amazon Personalize, you may find that you spend more time at this stage than the other stages. This is important and reflects that the quality of your data is the biggest factor in producing a usable and accurate model. This is where Amazon Personalize has an immediate effect—it’s both helping you and accelerating your progress.
Don’t worry about the format of the data, just the key fields being identified. Don’t get caught up in worrying about what model to use or the data it needs. Your focus is just on making your data accessible. If you’re just starting out in ML, you can get a basic dataset group working quickly with minimal data. If you’re a data scientist, you probably come back to this stage again to improve and add more data points (data features).
Creating a solution
When you have your dataset group with data in it, the next step is to create a solution. A solution covers two areas—selecting the model (recipe) and then using your data to train it. You have recipes and a popularity baseline from which to choose. Some of the recipes on offer include the following:
- Personalized reranking (search)
- SIMS—related items
- HRNN (Coldstart, Popularity-Baseline, and Metadata)—user personalization
If you’re not a data scientist, don’t worry. You can use AutoML, which runs your data against each of the available recipes. Amazon Personalize then judges the best recipe based on the accuracy results produced. This also covers changing some of the settings to get better results (hyperparameters). The following image shows a solution with the metric section at the bottom showing accuracy:
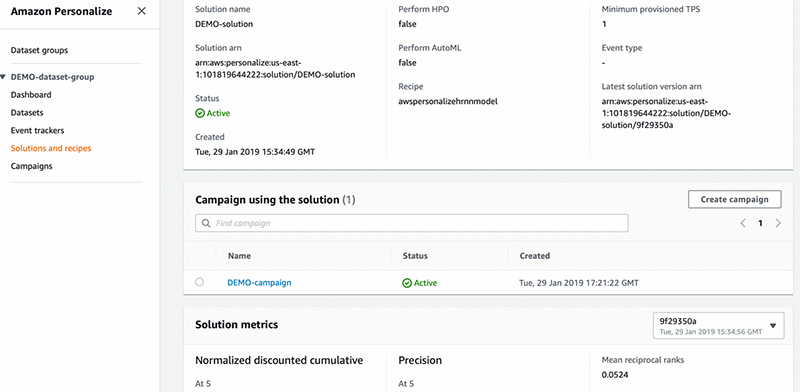
Amazon Personalize allows you to get something up and running quickly, even if you’re not a data scientist. This includes not just model selection and training, but restructuring the data into what each recipe requires and hiding the hassle of spinning up servers to run training jobs. If you are a data scientist, this is also good news, because you can take full control of the process.
Creating a campaign
After you have a solution version (a confirmed recipe and trained artifacts), it’s time to put it into action. This isn’t easy, and there is a lot to consider in running ML at scale.
To get you started, Amazon Personalize allows you to deploy a campaign (an inference engine for your recipe and the trained artifacts) as a PaaS. The campaign returns a REST API that you can use to produce recommendations. Here is an example of calling your API from Python:
get_recommendations_response = personalize_runtime.get_recommendations(
campaignArn = campaign_arn,
userId = str(user_id),
itemId = str(item_id)
)
item_list = get_recommendations_response['itemList']
The results:
Recommendations: [
"Full Monty, The (1997)",
"Chasing Amy (1997)",
"Fifth Element, The (1997)",
"Apt Pupil (1998)",
"Grosse Pointe Blank (1997)",
"My Best Friend's Wedding (1997)",
"Leaving Las Vegas (1995)",
"Contact (1997)",
"Waiting for Guffman (1996)",
"Donnie Brasco (1997)",
"Fargo (1996)",
"Liar (1997)",
"Titanic (1997)",
"English Patient, The (1996)",
"Willy Wonka and the Chocolate Factory (1971)",
"Chasing Amy (1997)",
"Star Trek: First Contact (1996)",
"Jerry Maguire (1996)",
"Last Supper, The (1995)",
"Hercules (1997)",
"Kolya (1996)",
"Toy Story (1995)",
"Private Parts (1997)",
"Citizen Ruth (1996)",
"Boogie Nights (1997)"
]
Conclusion
Amazon Personalize is a great addition to the AWS set of machine learning services. Its two-track approach allows you to quickly and efficiently get your first recommendation engine running and deliver immediate value to your end user or business. Then you can harness the depth and raw power of Amazon Personalize, which will keep you coming back to improve your recommendations.
Amazon Personalize puts a recommendation engine in the hands of every company and is now available in US East (Ohio), US East (N. Virginia), US West (Oregon), Asia Pacific (Tokyo), Asia Pacific (Singapore) and EU (Ireland). Well done, AWS!