
Amazon Textract - Automatically extract text and structured data from documents
Documents are a primary tool for record keeping, communication, collaboration, and transactions across many industries, including financial, medical, legal, and real estate. The millions of mortgage applications and hundreds of millions of W2 tax forms processed each year are just a few examples of such documents. A lot of information is locked in unstructured documents. It usually requires time-consuming and complex processes to enable search and discovery, business process automation, and compliance control for these documents.
In this post, I show how you can take advantage of Amazon Textract to automatically extract text and data from scanned documents without any machine learning (ML) experience. While AWS takes care of building, training, and deploying advanced ML models in a highly available and scalable environment, you take advantage of these models with simple-to-use API actions. Here are the use cases that I cover in this post:
- Text detection from documents
- Multi-column detection and reading order
- Natural language processing and document classification
- Natural language processing for medical documents
- Document translation
- Search and discovery
- Form extraction and processing
- Compliance control with document redaction
- Table extraction and processing
- PDF document processing
Amazon Textract
Before I get started with the use cases, let me review and introduce some of the core features. Amazon Textract goes beyond simple optical character recognition (OCR) to also identify the contents of fields in forms and information stored in tables. This allows you to use Amazon Textract to instantly “read” virtually any type of document and accurately extract text and data without the need for any manual effort or custom code.
The following images show an example document and corresponding extracted text, form, and table data using Amazon Textract in the AWS Management Console.
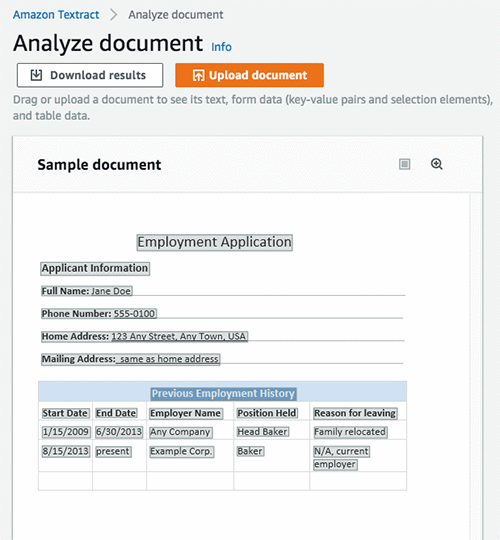
The following image shows the lines extracted as raw text from the document.
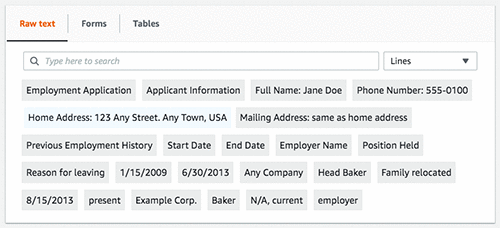
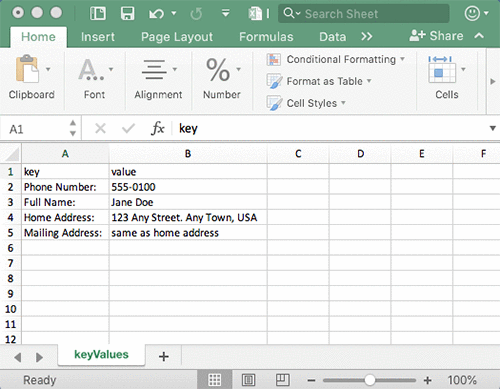
The following image shows the extracted form fields and their corresponding values.
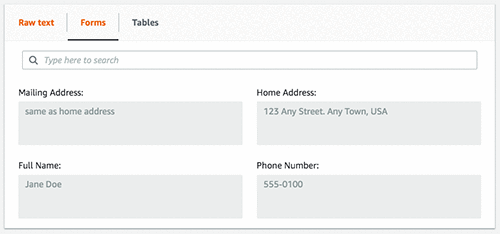
The following image shows the extracted table, cells, and the text in those cells.
To quickly download a zip file containing the output, choose Download results. You can choose various formats, including raw JSON, text, and CSV files for forms and tables.
In addition to the detected content, Amazon Textract provides additional information, like confidence scores and bounded boxes for detected elements. It gives you control on how you consume extracted content and integrate it into various business applications.
Amazon Textract provides both synchronous and asynchronous API actions to extract document text and analyze the document text data.
Synchronous APIs can be used for single-page documents and low latency use cases such as mobile capture. Asynchronous APIs can be used for multi-page documents such as PDF documents with thousands of pages. For more information, see the Amazon Textract API Reference.
Use cases
Now, write some code to take advantage of Amazon Textract API operations using the AWS SDK and see how easy it is to build power-smart applications. I will also use the JSON Parser Library for some of the below use cases.
Text detection from documents
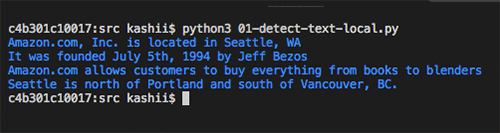
I start with a simple example on how to detect text from a document. Use the following image as an input document to Amazon Textract. As you can see, the sample image is not of good quality, but Amazon Textract can still detect the text with accuracy.

The following code example shows how to use a few lines of code to send this sample image to Amazon Textract and get a JSON response back. You then iterate over the blocks in JSON and print the detected text, as shown below.
import boto3
# Document
s3BucketName = "ki-textract-demo-docs"
documentName = "simple-document-image.jpg"
# Amazon Textract client
textract = boto3.client('textract')
# Call Amazon Textract
response = textract.detect_document_text(
Document={
'S3Object': {
'Bucket': s3BucketName,
'Name': documentName
}
})
#print(response)
# Print detected text
for item in response["Blocks"]:
if item["BlockType"] == "LINE":
print ('\033[94m' + item["Text"] + '\033[0m')
The following JSON response is what you receive from Amazon Textract, with blocks representing detected text in the document.
{
"Blocks": [
{
"Geometry": {
"BoundingBox": {
"Width": 1.0,
"Top": 0.0,
"Left": 0.0,
"Height": 1.0
},
"Polygon": [
{
"Y": 0.0,
"X": 0.0
},
{
"Y": 0.0,
"X": 1.0
},
{
"Y": 1.0,
"X": 1.0
},
{
"Y": 1.0,
"X": 0.0
}
]
},
"Relationships": [
{
"Type": "CHILD",
"Ids": [
"2602b0a6-20e3-4e6e-9e46-3be57fd0844b",
"82aedd57-187f-43dd-9eb1-4f312ca30042",
"52be1777-53f7-42f6-a7cf-6d09bdc15a30",
"7ca7caa6-00ef-4cda-b1aa-5571dfed1a7c"
]
}
],
"BlockType": "PAGE",
"Id": "8136b2dc-37c1-4300-a9da-6ed8b276ea97"
}.....
],
"DocumentMetadata": {
"Pages": 1
}
}
The following image shows the output of the detected
Multi-column detection and reading order
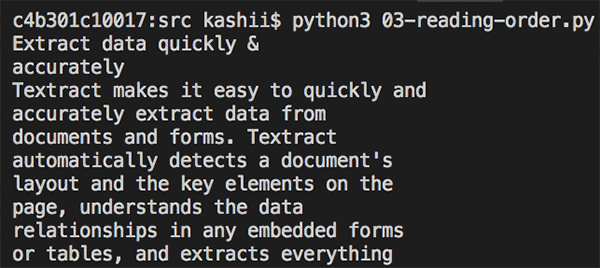
Traditional OCR solutions read left to right, do not detect multiple columns, and end up generating incorrect reading order for multi-column documents. In addition to detecting text, Amazon Textract provides additional geometry information that can be used to detect multiple columns and print the text in reading order. The following image is a two-column document. Similar to the earlier example, the image is not good quality but Amazon Textract still performs well.

The following example code shows processing the document with Amazon Textract and taking advantage of geometry information to print the text in reading order.
import boto3
# Document
s3BucketName = "ki-textract-demo-docs"
documentName = "two-column-image.jpg"
# Amazon Textract client
textract = boto3.client('textract')
# Call Amazon Textract
response = textract.detect_document_text(
Document={
'S3Object': {
'Bucket': s3BucketName,
'Name': documentName
}
})
#print(response)
# Detect columns and print lines
columns = []
lines = []
for item in response["Blocks"]:
if item["BlockType"] == "LINE":
column_found=False
for index, column in enumerate(columns):
bbox_left = item["Geometry"]["BoundingBox"]["Left"]
bbox_right = item["Geometry"]["BoundingBox"]["Left"] + item["Geometry"]["BoundingBox"]["Width"]
bbox_centre = item["Geometry"]["BoundingBox"]["Left"] + item["Geometry"]["BoundingBox"]["Width"]/2
column_centre = column['left'] + column['right']/2
if (bbox_centre > column['left'] and bbox_centre < column['right']) or (column_centre > bbox_left and column_centre < bbox_right):
#Bbox appears inside the column
lines.append([index, item["Text"]])
column_found=True
break
if not column_found:
columns.append({'left':item["Geometry"]["BoundingBox"]["Left"], 'right':item["Geometry"]["BoundingBox"]["Left"] + item["Geometry"]["BoundingBox"]["Width"]})
lines.append([len(columns)-1, item["Text"]])
lines.sort(key=lambda x: x[0])
for line in lines:
print (line[1])
The following image shows the output of the detected text in the correct reading order.
Natural language processing and document classification
Customer emails, support tickets, product reviews, social media, even advertising copy all represent insights into customer sentiment that can be put to work for your business.
A lot of such content contains images or scanned versions of documents. After text is extracted from these documents, you can use Amazon Comprehend to detect sentiment, entities, key phrases, syntax and topics. You can also train Amazon Comprehend to detect custom entities based on your business domain. These insights can then be used to classify documents, automate business process workflows, and ensure compliance.
The following example code shows processing the first image sample used earlier with Amazon Textract to extract text and then using Amazon Comprehend to detect sentiment and entities.
import boto3
# Document
s3BucketName = "ki-textract-demo-docs"
documentName = "simple-document-image.jpg"
# Amazon Textract client
textract = boto3.client('textract')
# Call Amazon Textract
response = textract.detect_document_text(
Document={
'S3Object': {
'Bucket': s3BucketName,
'Name': documentName
}
})
#print(response)
# Print text
print("\nText\n========")
text = ""
for item in response["Blocks"]:
if item["BlockType"] == "LINE":
print ('\033[94m' + item["Text"] + '\033[0m')
text = text + " " + item["Text"]
# Amazon Comprehend client
comprehend = boto3.client('comprehend')
# Detect sentiment
sentiment = comprehend.detect_sentiment(LanguageCode="en", Text=text)
print ("\nSentiment\n========\n{}".format(sentiment.get('Sentiment')))
# Detect entities
entities = comprehend.detect_entities(LanguageCode="en", Text=text)
print("\nEntities\n========")
for entity in entities["Entities"]:
print ("{}\t=>\t{}".format(entity["Type"], entity["Text"]))
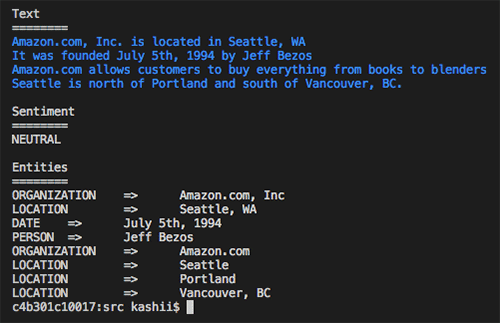
The following image shows the output text along with the text analysis from Amazon Comprehend. You can see that it found the sentiment to be “Neutral” and detected “Amazon” as an organization, “Seattle, WA” as a location and “July 5th, 1994” as a date, along with other entities.
Natural language processing for medical documents
One of the important ways to improve patient care and accelerate clinical research is by understanding and analyzing the insights and relationships that are “trapped” in free-form medical text. These can include hospital admission notes and a patient’s medical history. In this example, use the following document to extract text using Amazon Textract. You then use Amazon Comprehend Medical to extract medical entities, such as medical condition, medication, dosage, strength, and protected health information (PHI).

The following example code shows how different medical entities are detected.
import boto3
# Document
s3BucketName = "ki-textract-demo-docs"
documentName = "medical-notes.png"
# Amazon Textract client
textract = boto3.client('textract')
# Call Amazon Textract
response = textract.detect_document_text(
Document={
'S3Object': {
'Bucket': s3BucketName,
'Name': documentName
}
})
#print(response)
# Print text
print("\nText\n========")
text = ""
for item in response["Blocks"]:
if item["BlockType"] == "LINE":
print ('\033[94m' + item["Text"] + '\033[0m')
text = text + " " + item["Text"]
# Amazon Comprehend client
comprehend = boto3.client('comprehendmedical')
# Detect medical entities
entities = comprehend.detect_entities(Text=text)
print("\nMidical Entities\n========")
for entity in entities["Entities"]:
print("- {}".format(entity["Text"]))
print (" Type: {}".format(entity["Type"]))
print (" Category: {}".format(entity["Category"]))
if(entity["Traits"]):
print(" Traits:")
for trait in entity["Traits"]:
print (" - {}".format(trait["Name"]))
print("\n")
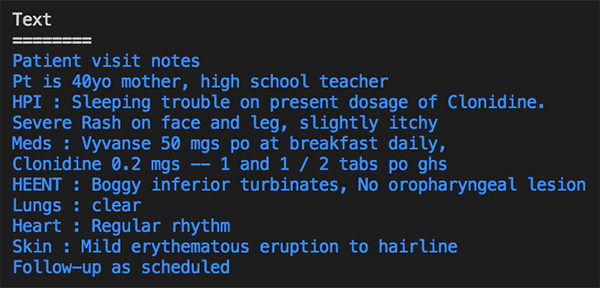
The following image and text block shows the output of the detected text with information categorized by type. It detected “40yo” as the age with category “Protected Health Information”. It also detected different medical conditions, including sleeping trouble, rash, inferior turbinates, erythematous eruption, and others. It recognized different medications and anatomy information.
Medical Entities
========
- 40yo
Type: AGE
Category: PROTECTED_HEALTH_INFORMATION
- Sleeping trouble
Type: DX_NAME
Category: MEDICAL_CONDITION
Traits:
- SYMPTOM
- Clonidine
Type: GENERIC_NAME
Category: MEDICATION
- Rash
Type: DX_NAME
Category: MEDICAL_CONDITION
Traits:
- SYMPTOM
- face
Type: SYSTEM_ORGAN_SITE
Category: ANATOMY
- leg
Type: SYSTEM_ORGAN_SITE
Category: ANATOMY
- Vyvanse
Type: BRAND_NAME
Category: MEDICATION
- Clonidine
Type: GENERIC_NAME
Category: MEDICATION
- HEENT
Type: SYSTEM_ORGAN_SITE
Category: ANATOMY
- Boggy inferior turbinates
Type: DX_NAME
Category: MEDICAL_CONDITION
Traits:
- SIGN
- inferior
Type: DIRECTION
Category: ANATOMY
- turbinates
Type: SYSTEM_ORGAN_SITE
Category: ANATOMY
- oropharyngeal lesion
Type: DX_NAME
Category: MEDICAL_CONDITION
Traits:
- SIGN
- NEGATION
- Lungs
Type: SYSTEM_ORGAN_SITE
Category: ANATOMY
- clear Heart
Type: DX_NAME
Category: MEDICAL_CONDITION
Traits:
- SIGN
- Heart
Type: SYSTEM_ORGAN_SITE
Category: ANATOMY
- Regular rhythm
Type: DX_NAME
Category: MEDICAL_CONDITION
Traits:
- SIGN
- Skin
Type: SYSTEM_ORGAN_SITE
Category: ANATOMY
- erythematous eruption
Type: DX_NAME
Category: MEDICAL_CONDITION
Traits:
- SIGN
- hairline
Type: SYSTEM_ORGAN_SITE
Category: ANATOMY
Document translation
Many organizations localize content for international users, such as websites and applications. They must translate large volumes of documents efficiently. You can use Amazon Textract along with Amazon Translate to extract text and data and then translate them into other languages.
The following code example shows translating the text in the first image to German.
import boto3
# Document
s3BucketName = "ki-textract-demo-docs"
documentName = "simple-document-image.jpg"
# Amazon Textract client
textract = boto3.client('textract')
# Call Amazon Textract
response = textract.detect_document_text(
Document={
'S3Object': {
'Bucket': s3BucketName,
'Name': documentName
}
})
#print(response)
# Amazon Translate client
translate = boto3.client('translate')
print ('')
for item in response["Blocks"]:
if item["BlockType"] == "LINE":
print ('\033[94m' + item["Text"] + '\033[0m')
result = translate.translate_text(Text=item["Text"], SourceLanguageCode="en", TargetLanguageCode="de")
print ('\033[92m' + result.get('TranslatedText') + '\033[0m')
print ('')
The following image shows the output of the detected text, translated to German line by line.

Search and discovery
Extracting structured data from documents and creating a smart index using Amazon Elasticsearch Service (Amazon ES) allows you to search through millions of documents quickly. For example, a mortgage company could use Amazon Textract to process millions of scanned loan applications in a matter of hours and have the extracted data indexed in Amazon ES. This would allow them to create search experiences like searching for loan applications where the applicant name is John Doe, or searching for contracts where the interest rate is 2 percent.
The following code example shows how you can extract text from the first image, store it in Amazon ES, and then search it using Kibana. You can also build a custom UI experience by taking advantage of the Amazon ES APIs. Later in the post, as you learn how to extract forms and tables, that structured data can then be indexed similarly to enable smart search.
import boto3
from elasticsearch import Elasticsearch, RequestsHttpConnection
from requests_aws4auth import AWS4Auth
def indexDocument(bucketName, objectName, text):
# Update host with endpoint of your Elasticsearch cluster
#host = "search--xxxxxxxxxxxxxx.us-east-1.es.amazonaws.com
host = "searchxxxxxxxxxxxxxxxx.us-east-1.es.amazonaws.com"
region = 'us-east-1'
if(text):
service = 'es'
ss = boto3.Session()
credentials = ss.get_credentials()
region = ss.region_name
awsauth = AWS4Auth(credentials.access_key, credentials.secret_key, region, service, session_token=credentials.token)
es = Elasticsearch(
hosts = [{'host': host, 'port': 443}],
http_auth = awsauth,
use_ssl = True,
verify_certs = True,
connection_class = RequestsHttpConnection
)
document = {
"name": "{}".format(objectName),
"bucket" : "{}".format(bucketName),
"content" : text
}
es.index(index="textract", doc_type="document", id=objectName, body=document)
print("Indexed document: {}".format(objectName))
# Document
s3BucketName = "ki-textract-demo-docs"
documentName = "simple-document-image.jpg"
# Amazon Textract client
textract = boto3.client('textract')
# Call Amazon Textract
response = textract.detect_document_text(
Document={
'S3Object': {
'Bucket': s3BucketName,
'Name': documentName
}
})
#print(response)
# Print detected text
text = ""
for item in response["Blocks"]:
if item["BlockType"] == "LINE":
print ('\033[94m' + item["Text"] + '\033[0m')
text += item["Text"]
indexDocument(s3BucketName, documentName, text)
# You can view index documents in Kibana Dashboard
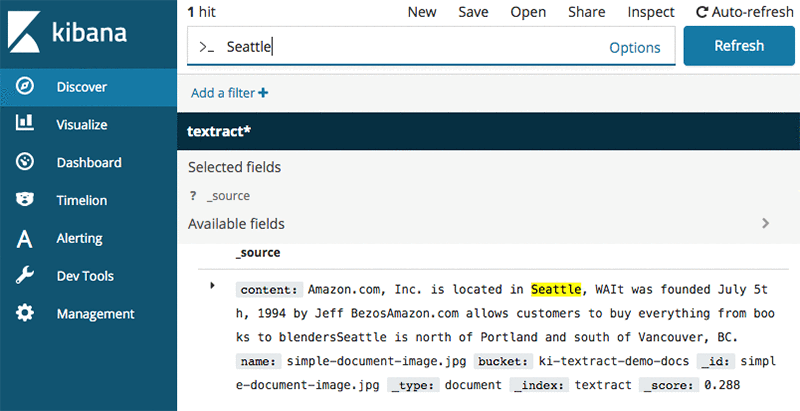
The following image shows the output of extracted text in Kibana search results.
Form extraction and processing
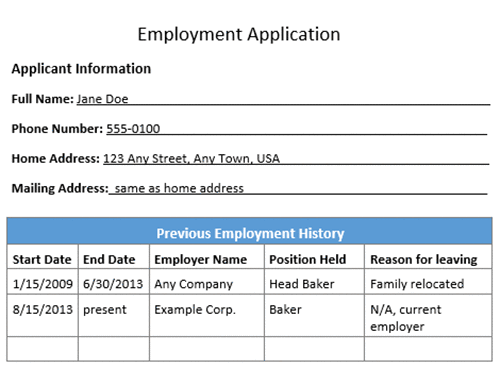
Amazon Textract can provide the inputs required to automatically process forms without human intervention. For example, a bank could write code to read PDFs of loan applications. The information contained in the document could be used to initiate all of the necessary background and credit checks to approve the loan so that customers can get instant results for their application rather than having to wait several days for manual review and validation. The following image is an employment application with form fields and a table.
The following code example shows how to extract forms from the employment application and process different fields.
import boto3
from trp import Document
# Document
s3BucketName = "ki-textract-demo-docs"
documentName = "employmentapp.png"
# Amazon Textract client
textract = boto3.client('textract')
# Call Amazon Textract
response = textract.analyze_document(
Document={
'S3Object': {
'Bucket': s3BucketName,
'Name': documentName
}
},
FeatureTypes=["FORMS"])
#print(response)
doc = Document(response)
for page in doc.pages:
# Print fields
print("Fields:")
for field in page.form.fields:
print("Key: {}, Value: {}".format(field.key, field.value))
# Get field by key
print("\nGet Field by Key:")
key = "Phone Number:"
field = page.form.getFieldByKey(key)
if(field):
print("Key: {}, Value: {}".format(field.key, field.value))
# Search fields by key
print("\nSearch Fields:")
key = "address"
fields = page.form.searchFieldsByKey(key)
for field in fields:
print("Key: {}, Value: {}".format(field.key, field.value))
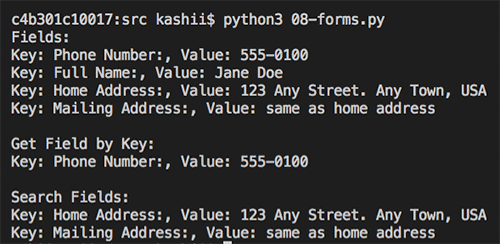
The following image is the output of detected form for the employment application.
Compliance control with document redaction
Because Amazon Textract identifies data types and form labels automatically, AWS helps secure infrastructure so that you can maintain compliance with information controls. For example, an insurer could use Amazon Textract to feed a workflow that automatically redacts personally identifiable information (PII) for review before archiving claim forms. Amazon Textract recognizes the important fields that require protection.
The following code example shows extracting all the form fields in the employment application used earlier, and then redacting all the address fields.
import boto3
from trp import Document
from PIL import Image, ImageDraw
# Document
s3BucketName = "ki-textract-demo-docs"
documentName = "employmentapp.png"
# Amazon Textract client
textract = boto3.client('textract')
# Call Amazon Textract
response = textract.analyze_document(
Document={
'S3Object': {
'Bucket': s3BucketName,
'Name': documentName
}
},
FeatureTypes=["FORMS"])
#print(response)
doc = Document(response)
# Redact document
img = Image.open(documentName)
width, height = img.size
if(doc.pages):
page = doc.pages[0]
for field in page.form.fields:
if(field.key and field.value and "address" in field.key.text.lower()):
#if(field.key and field.value):
print("Redacting => Key: {}, Value: {}".format(field.key.text, field.value.text))
x1 = field.value.geometry.boundingBox.left*width
y1 = field.value.geometry.boundingBox.top*height-2
x2 = x1 + (field.value.geometry.boundingBox.width*width)+5
y2 = y1 + (field.value.geometry.boundingBox.height*height)+2
draw = ImageDraw.Draw(img)
draw.rectangle([x1, y1, x2, y2], fill="Black")
img.save("redacted-{}".format(documentName))
The following image is the output redacted version of employment application.
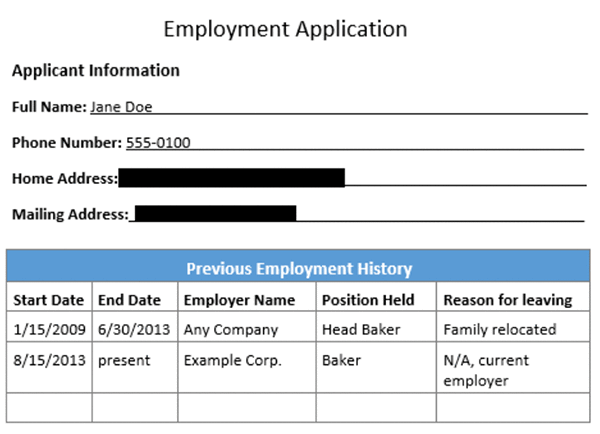
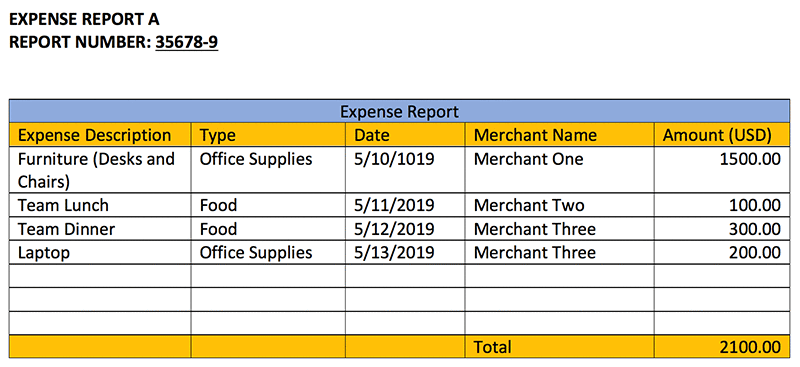
Table extraction and processing
Amazon Textract can detect tables and their content. A company can extract all the amounts from an expense report and apply rules, such as any expense more than $1000 needs extra review.
The following code example uses the expense report sample document and prints the content of each cell, along with a warning message if any expense is more than $1000.
import boto3
from trp import Document
# Document
s3BucketName = "ki-textract-demo-docs"
documentName = "expense.png"
# Amazon Textract client
textract = boto3.client('textract')
# Call Amazon Textract
response = textract.analyze_document(
Document={
'S3Object': {
'Bucket': s3BucketName,
'Name': documentName
}
},
FeatureTypes=["TABLES"])
#print(response)
doc = Document(response)
def isFloat(input):
try:
float(input)
except ValueError:
return False
return True
warning = ""
for page in doc.pages:
# Print tables
for table in page.tables:
for r, row in enumerate(table.rows):
itemName = ""
for c, cell in enumerate(row.cells):
print("Table[{}][{}] = {}".format(r, c, cell.text))
if(c == 0):
itemName = cell.text
elif(c == 4 and isFloat(cell.text)):
value = float(cell.text)
if(value > 1000):
warning += "{} is greater than $1000.".format(itemName)
if(warning):
print("\nReview needed:\n====================\n" + warning)
The following text is the output of the table cells and the text within.
Table[0][0] = Expense Description
Table[0][1] = Type
Table[0][2] = Date
Table[0][3] = Merchant Name
Table[0][4] = Amount (USD)
Table[1][0] = Furniture (Desks and Chairs)
Table[1][1] = Office Supplies
Table[1][2] = 5/10/1019
Table[1][3] = Merchant One
Table[1][4] = 1500.00
Table[2][0] = Team Lunch
Table[2][1] = Food
Table[2][2] = 5/11/2019
Table[2][3] = Merchant Two
Table[2][4] = 100.00
Table[3][0] = Team Dinner
Table[3][1] = Food
Table[3][2] = 5/12/2019
Table[3][3] = Merchant Three
Table[3][4] = 300.00
Table[4][0] = Laptop
Table[4][1] = Office Supplies
Table[4][2] = 5/13/2019
Table[4][3] = Merchant Three
Table[4][4] = 200.00
Table[5][0] =
Table[5][1] =
Table[5][2] =
Table[5][3] =
Table[5][4] =
Table[6][0] =
Table[6][1] =
Table[6][2] =
Table[6][3] =
Table[6][4] =
Table[7][0] =
Table[7][1] =
Table[7][2] =
Table[7][3] =
Table[7][4] =
Table[8][0] =
Table[8][1] =
Table[8][2] =
Table[8][3] = Total
Table[8][4] = 2100.00
Review needed:
====================
Furniture (Desks and Chairs) is greater than $1000.
PDF document processing (async API operations)
For the earlier examples, you used images with the sync API operations. Now, see how you can process PDF files using the async API operations.
First, use StartDocumentTextDetection or StartDocumentAnalysis to start an Amazon Textract job. As the job completes, Amazon Textract publishes the results of an Amazon Textract request, including completion status, to Amazon SNS. You can then use GetDocumentTextDetection or GetDocumentAnalysis to get the results from Amazon Textract.
The following code example shows how to start a job, get job status, and then process the results. Click here for the sample PDF document. For more information, see Calling Amazon Textract Asynchronous Operations.
import boto3
import time
def startJob(s3BucketName, objectName):
response = None
client = boto3.client('textract')
response = client.start_document_text_detection(
DocumentLocation={
'S3Object': {
'Bucket': s3BucketName,
'Name': objectName
}
})
return response["JobId"]
def isJobComplete(jobId):
# For production use cases, use SNS based notification
# Details at: https://docs.aws.amazon.com/textract/latest/dg/api-async.html
time.sleep(5)
client = boto3.client('textract')
response = client.get_document_text_detection(JobId=jobId)
status = response["JobStatus"]
print("Job status: {}".format(status))
while(status == "IN_PROGRESS"):
time.sleep(5)
response = client.get_document_text_detection(JobId=jobId)
status = response["JobStatus"]
print("Job status: {}".format(status))
return status
def getJobResults(jobId):
pages = []
client = boto3.client('textract')
response = client.get_document_text_detection(JobId=jobId)
pages.append(response)
print("Resultset page recieved: {}".format(len(pages)))
nextToken = None
if('NextToken' in response):
nextToken = response['NextToken']
while(nextToken):
response = client.get_document_text_detection(JobId=jobId, NextToken=nextToken)
pages.append(response)
print("Resultset page recieved: {}".format(len(pages)))
nextToken = None
if('NextToken' in response):
nextToken = response['NextToken']
return pages
# Document
s3BucketName = "ki-textract-demo-docs"
documentName = "Amazon-Textract-Pdf.pdf"
jobId = startJob(s3BucketName, documentName)
print("Started job with id: {}".format(jobId))
if(isJobComplete(jobId)):
response = getJobResults(jobId)
#print(response)
# Print detected text
for resultPage in response:
for item in resultPage["Blocks"]:
if item["BlockType"] == "LINE":
print ('\033[94m' + item["Text"] + '\033[0m')
The following image shows the job status as the API call proceeds.
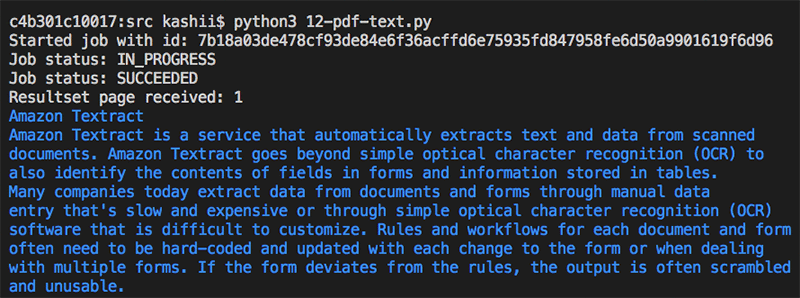
Conclusion
In this post, I showed you how to use Amazon Textract to automatically extract text and data from scanned documents without any machine learning (ML) experience. I covered use cases in fields such as finance, healthcare, and HR, but there are many other opportunities where the ability to unlock text and data from unstructured documents could be most useful. To learn more about Amazon Textract, read about processing single-page and multi-page documents, working with block objects, and code samples.
You can start using Amazon Textract in US East (N. Virginia), US East (Ohio), US West (Oregon), and EU (Ireland) today.